MLE4 : Evaluating Data Science Platforms ~ Real Data, Practical Tooling
- 3 minsA machine learning solution is made up of a number of services that include data management to clean and transform data, compute services to engineer features and train models, software engineering tools to orchestrate and schedule the workflow as well as dashboarding to visualize the results and interact with the data real-time. Building a platform that integrates with the existing environment and centralizing these components from scratch can be quite a challenging journey to undertake for most organizations in-house. AutoML models have received a lot of attention as they become the next evolutionary step in response to these challenges. They can be thought of as the process of automating some steps of the machine learning process with minimal human effort and without compromising on the model’s performance. They are often pitched as being effcient and easier to use while outperforming manually developed machine learning models for classification tasks as an example in point.
While the early versions of open-source AutoML solutions originated from academia,they were limited in support for workflow steps that extended to feature extraction and engineering, model evaluation, deployment and monitoring. The recent wave of enterprise AutoML solutions are developed mostly by the major cloud providers are more comprehensive while offering scalability, flexibility and explanability capabilities. Unlike a mainstream system design where tasks are run in a monolith fashion, these models abstract easch part of the ML workflow into an independent service as it scales.
I present a comparative study on some AutoML solutions from both cloud vendors and third-party solutions as they have attempted to abstract this complexity through managed machine learning services by focusing on key aspects of the core layers in terms of their functionalities and perfomance on experiments involving high dimensional dataset and multi-clas problems.
- AWS Sagemaker
- Google’s AutoML
- Databricks AutoML
- Alteryx
- Dataiku
- H2O
Google introduced its Cloud AutoML framework in 2018 to offer automated machine learning capabilites to non ML experts and democratize data science. It automates the process of algorithm selection wherein the citizen data scientist does not need to choose which model is appropiate and build the framework. They can focus on the busines problem without getting lost with the technicalities or expertise to get an optimized model. Inset is a schematic overview of the MLOps pipeline from Google cloud. On the other hand, Databricks creates and evaluates models that are constructed from open source components - from the scikit-learn (classification and regression models), XG-boost and LightGBM packages and integrated into machine learninig pipelines.
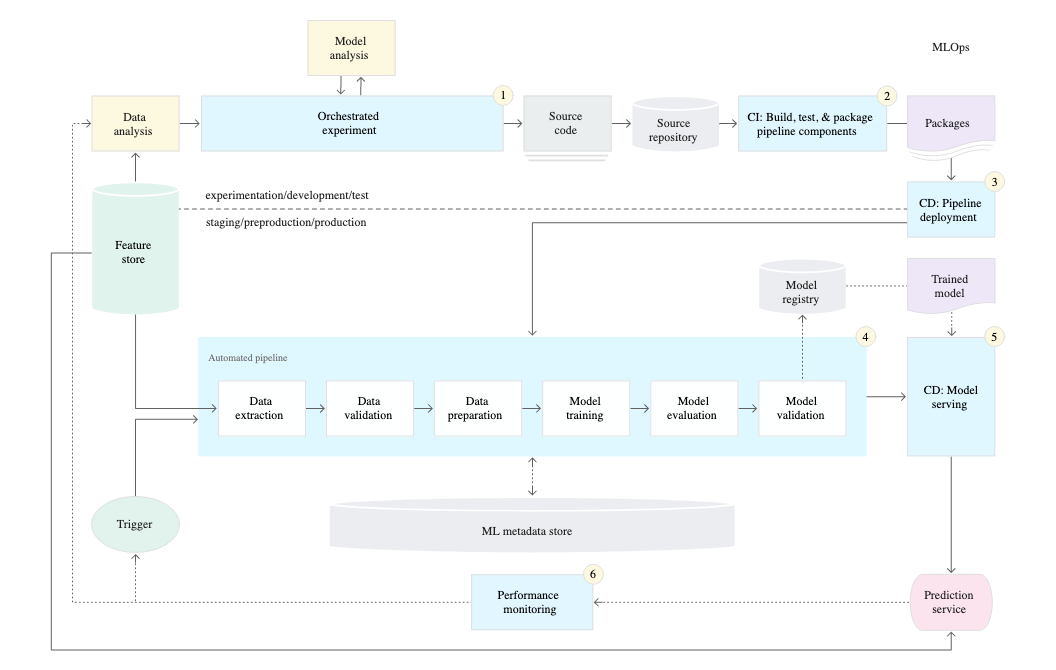
If an organization wants the power and flexibility of their own MLOps architecture, then the following open source components can be used to set up the system.
- JupyterHub - shared notebook for team collaboration
- Seldon - to productionize the models
- MLFlow - to track experiments and models
MLFlow is apt as an experiment tracker cum model registry as it automates model updating when it gets outdated and need to be trained on new data. It is an answer to proactively identifying model decay without manual retraining. Simply put, MLFlow is designed to track models, model parameters and hyperpararmeters for reproducability. It is an open source project that one can easily install by running the following command in anaconda prompt :
pip install mlflow
You should see this if its already installed (as in my case) :

- Apache Airflow - to manage workflows and schedule tasks
- Dash, Shiny - dashboarding tools
In conclusion, an MLOps architecture should strive to overcome the challenges around reproducability, accountability, collaborativeness and continuous development. Without a solid strategy to guide the adoption, a lot of things can fail along the way. In embarking on machine learning as a service solutions, organizations need to fundamentally ask these threee questions :
1) Is the technology trustworthy and reliable? Can its output be trusted to produce fair outcomes?
2) Does the solution support diverse business objectives and its interoperability capacity with different technology platforms?
3) Is the output reproducable and scalable?