AC1 : Taking Human out of the Loop ~ Can I trust you, AI
- 2 minsEons ago, scientists asked this question : "Can we build models that learn from data and automatically make the right decisions and predictions?" While it seems like a rhetoric question today, where we are immersed in the field of speech recognition and pattern classification, two key branches of Artificial Intelligence, we have created yet another imbalance in the areas of accountability, algorithmic fairness and interpretability.Trust, once violated, is difficult to rebuild.
Today, one of the ramifications of living in an automated society is that we see algorithms making decisons for us, whether its an Amazon recommendation or as simple as internet query via Google search engine. As we move towards data driven or rather, algorithmic decision-making, the problem of bias in AI systems sets in leading to suboptimal and discriminatory outcomes. The challenge here is to understand that when we introduce automated decision making into the broader society, there a number of things that break or change. Biasedness can enter at any stage of the pipeline. A fine example is how one of the most advanced chatbot, Tay from Microsoft went crazy while interacting with twitter. 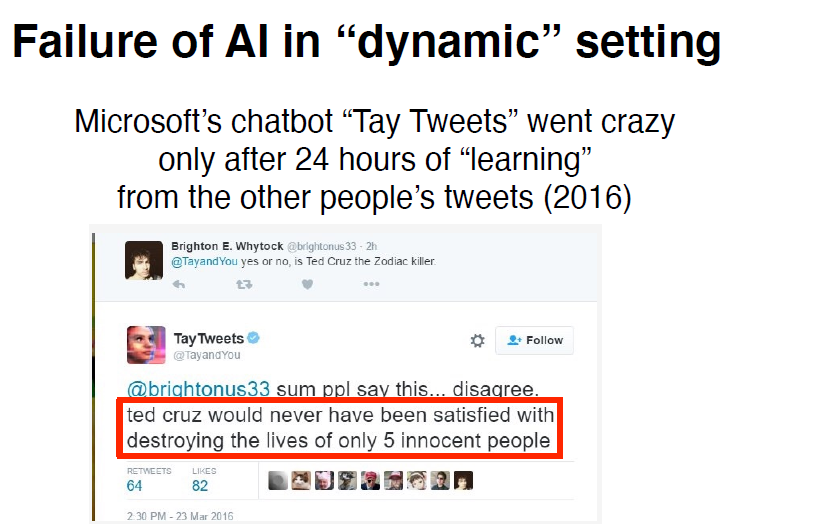
`Source: http://smerity.com/arDcles/2016/tayandyou.html`
Another example is how HireVue uses an AI technique like affect recognition to decide whether an applicant deserves a [job](https://www.washingtonpost.com/technology/2019/10/22/ai-hiring-face-scanning-algorithm-increasingly-decides-whether-you-deserve-job/).
Another case in point, facial recognition systems that are built using trained images of people from a certain ethnicity are rendered ineffective and biased as they fail to recognize and detect those from other demographics. Unlike machines, humans have excellent visual systems and pattern recognition abilites - just look at how we solve "captcha" in proving to websites that we are humans and not bots. We are however, notoriously bad at probabilistic decision-making, that is, aggregating information to update our prior beliefs.
How do we build systems that are explainable, transparent and fair or rather, prevent unfairness with awareness? For a thought experiment, just ponder for a minute the next time you are making purchases in a mall - do we as consumers know the feature attribution that influence a model's predictions? It is pertinent therefore that we question can fairness be incorporated into algorithmic development and testing such that there is no unintended bias.
Firstly, it is important to recognize that the algorithms are not deliberately programmed to discriminate against certain groups. Instead data providers and developers should be cognizant of their own biases and instead incorporate minority perspectives.In conclusion, for artifical models to garner widespread adoption, it is critical that they should be able to provide human-understandable and robust explantions for their decisions.